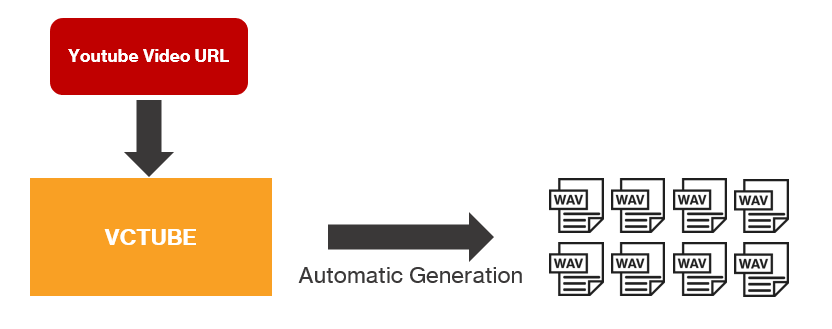
Youtube URL을 이용해서 음성합성 데이터셋 생성
- 등록자 최성
- 등록일 2020-11-26 06:09 (2021-09-15 11:32)
- 조회수 3710
좋아요
 2
2
 2
2
22
튜토리얼 영상
Generate Speech Dataset by VCTUBE
VCTUBE 프로젝트 소개
- VCTUBE는 음성합성을 위한 딥러닝 모델 학습을 위한 음성합성 데이터셋을 Youtube URL로부터 자동으로 생성해주는 파이썬 라이브러리
- 스피치 데이터셋은 아래의 첫번째 그림과 같이 오디오와 그에 해당하는 자막으로 이루어진 데이터셋입니다. TTS 모델을 학습시키기 위해서는 10시간 이상의 스피치 데이터셋이 필요합니다. 하지만 10시간 이상의 음성합성 데이터셋을 구하거나 직접 생성하기에는 많은 시간과 비용이 요구됩니다.
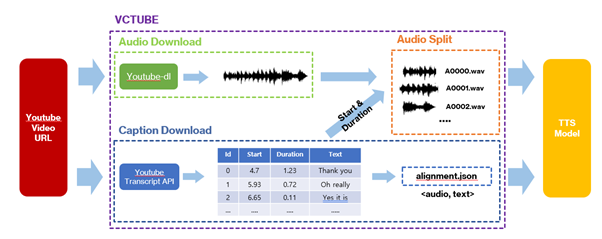
- VCTUBE는 두번째 그림과 같이 3단계로 구성되어 있습니다. Youtube 영상으로부터 오디오파일을 다운로드하는 Audio Download, 영상으로부터 자막파일을 다운로드하는 Caption Download, 마지막으로 자막에 맞게 오디오를 나누는 Audio Split단계로 이루어져 있습니다.

스피치 데이터셋 생성 실습 준비 단계
from vctube import VCtubeplaylist_name = 'Obama_Speech'playlist_url = 'https://www.youtube.com/watch?v=bps3m4eFTuE'- lang = 'en'
- vc = VCtube(playlist_name, playlist_url, lang)
- 우선 VCTUBE를 통해서 데이터를 생성하기 전에 Youtube 영상 URL, 해당 영상의 자막 그리고 저장될 폴더의 이름을 지정해야 합니다.
- 저장될 폴더 이름은 playlist_name로 변수를 설정했으며 해당 변수에는 Obama_Speech를 지정해줬습니다.
- 영상의 자막 언어가 영어로 되어있기에 영상 자막의 언어를 의미하는 lang이라는 변수를 선언하고 영어로 설정하기 위해서 ‘en’ 지정해줍니다.
- 영상에 사용될 URL은 playlist_url 변수에 실제 영상 URL을 지정해줬습니다.
- 이번 실습에서 사용될 영상은 오바마 미국 전 대통령의 20분 분량의 연설 영상입니다. https://www.youtube.com/watch?v=bps3m4eFTuE
- 마지막으로 VCTUBE가 동작하기 위해서 생성자에 앞서 설정한 폴더이름, 영상 URL, 언어를 지정하고 실행합니다.
- 이때 변수의 이름은 변경이 가능합니다.
제 스피치 데이터셋 생성 실습 [ Audio Download Step ]
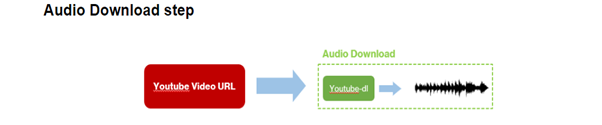
vc.download_audio()
- 이후 앞서 생성한 생성자(vc)를 통해 vc.download_audio() 함수를 실행시키면 해당 영상의 전체 음성 파일이 .wav 형식으로 미리 지정한 폴더에 (Obama_Speech) 저장됩니다.
- 만약 선택한 Youtube URL이 여러 개의 영상으로 이루어진 영상 재생목록이라면 영상의 개수에 맞게 여러 음성 파일이 생성됩니다.
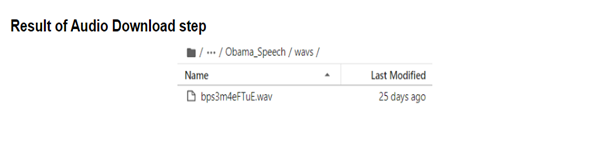
- Obama_Speech 폴더 내부에 하나의 .wav 폴더가 생성되었고 해당 폴더에 전체 영상의 음성파일이 생성된 것을 확인할 수 있습니다.
- 이때 영상의 이름은 항상 URL의 후반부로 지정됩니다.
vc.download_audio()
- 이후 앞서 생성한 생성자(vc)를 통해 vc.download_audio() 함수를 실행시키면 해당 영상의 전체 음성 파일이 .wav 형식으로 미리 지정한 폴더에 (Obama_Speech) 저장됩니다.
- 만약 선택한 Youtube URL이 여러 개의 영상으로 이루어진 영상 재생목록이라면 영상의 개수에 맞게 여러 음성 파일이 생성됩니다.
- Obama_Speech 폴더 내부에 하나의 .wav 폴더가 생성되었고 해당 폴더에 전체 영상의 음성파일이 생성된 것을 확인할 수 있습니다.
- 이때 영상의 이름은 항상 URL의 후반부로 지정됩니다.
실제 스피치 데이터셋 생성 실습 [ Caption Download Step ]
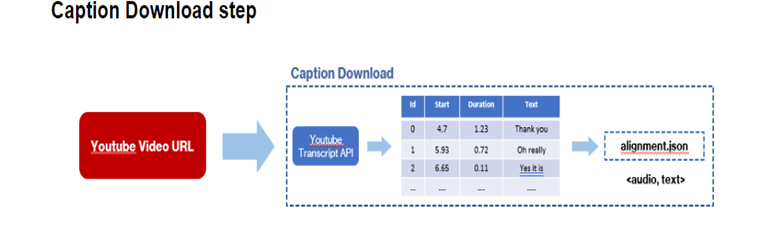
vc.download_captions()- 생성자를 통해 vc.download_catptions() 함수를 실행하면 해당 Youtube 영상의 자막파일을 여러가지 파일 형식으로 다운로드 합니다.
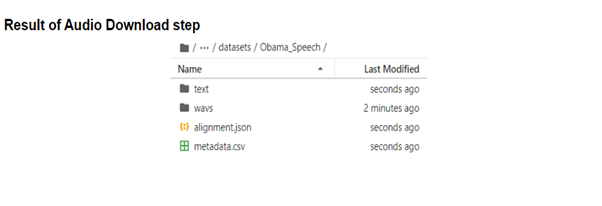
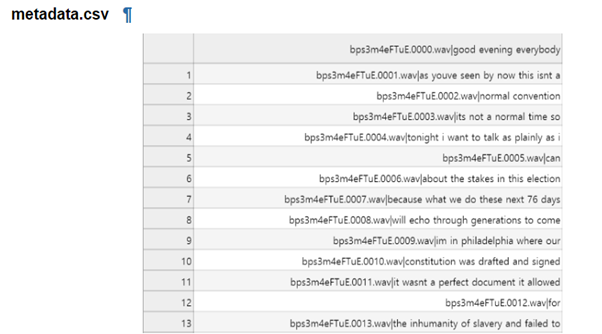
- 실행 이후 Obama_Speech 폴더를 확인하면 alignment.json, metadata.csv와 texts 폴더가 생성된 걸 확인할 수 있습니다.
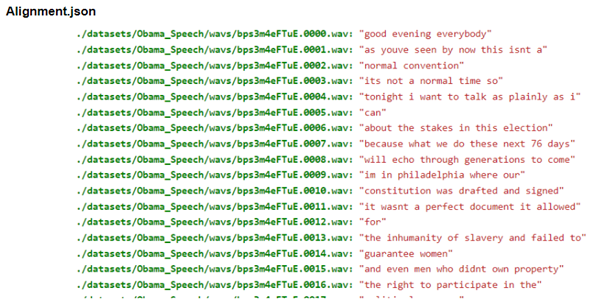
- alignment.json 파일에는 VCTUBE의 데이터셋 생성의 마지막 단계인 audio_split단계에서 생성될 파일의 경로와 해당 오디오파일의 자막으로 구성됩니다.
- metadata.csv 파일에는 VCTUBE의 데이터셋 생성의 마지막 단계인 audio_split단계에서 생성될 파일의 이름과 해당 오디오 파일의 자막으로 구성됩니다.
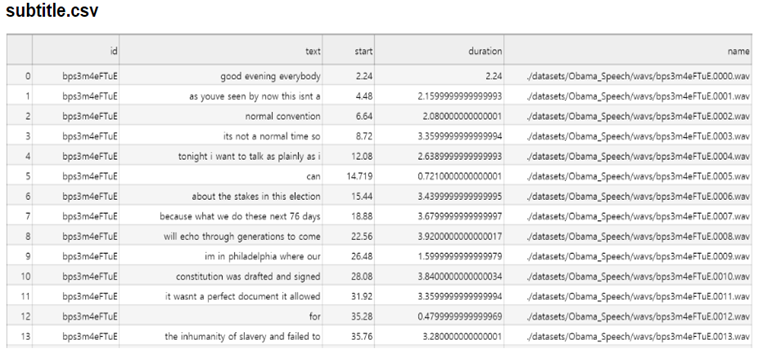
- texts폴더에 subtitle.csv 파일은 오디오 파일 id(URL 후반부), 자막, 해당 자막의 영상 시작시간(start)과 재생시간(duration) 그리고 audio_split단계에서 생성될 파일의 경로로 구성 되어있습니다.
- Subtitle.csv파일의 자막 시작시간(start)과 재생시간(duration)을 토대로 추후 audio_split단계에서 앞서 첫번째 오디오 다운로드 스텝에서 다운로드한 오디오 파일을 자막에 맞는 오디오 파일들을 생성합니다.
실제 스피치 데이터셋 생성 실습 [ Audio Split Step ]
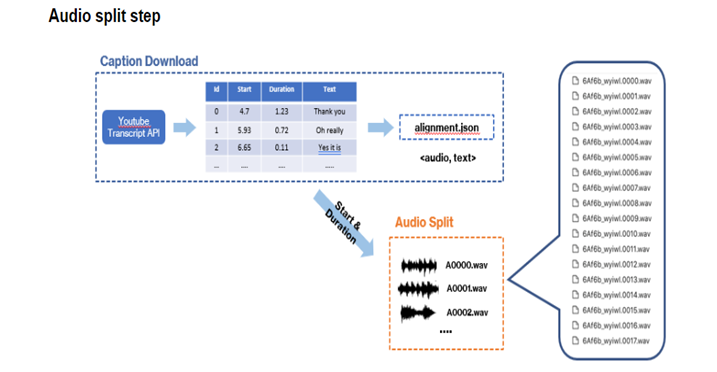
vc.audio_split()- 마지막 오디오 스플릿 단계에서는 vc.audio_split() 함수를 실행하면 처음에 다운로드 받은 오디오 파일을 각 자막에 맞는 길이로 나눠서 여러 개의 오디오 파일을 생성합니다.
- 함수 실행 후 해당 폴더(Obama_Speech)의 wavs폴더에 자막에 맞게 나뉘어진 여러 개의 파일을 볼 수 있습니다.
vc.audio_split()- 마지막 오디오 스플릿 단계에서는 vc.audio_split() 함수를 실행하면 처음에 다운로드 받은 오디오 파일을 각 자막에 맞는 길이로 나눠서 여러 개의 오디오 파일을 생성합니다.
- 함수 실행 후 해당 폴더(Obama_Speech)의 wavs폴더에 자막에 맞게 나뉘어진 여러 개의 파일을 볼 수 있습니다.
(한국어, 일본어) 스피치 데이터셋 생성 실습 준비단계

from vctube import VCtube
Korean_folder="Korean"
Japanese_folder = 'Japanese'
Korean_url = "https://www.youtube.com/watch?v=dOYaWLddRbU"
Japanese_url = 'https://www.youtube.com/watch?v=3k75rkB61Bk'
Korean = "ko" #ex) ko, en, fr, de, ja...
Japanese = "ja"
Korean_VCTUBE = VCtube(Korean_folder, Korean_url, Korean)
Japanese_VCTUBE = VCtube(Japanese_folder, Japanese_url, Japanese)- VCTUBE는 다양한 언어로 이루어진 스피치 데이터셋을 생성 할 수 있습니다.
- 이번 실습에서는 한국어와 일본어 영상을 통해서 각각의 스피치 데이터셋을 생성하도록 하겠습니다.
- 이전 실습과 같이 데이터가 저장될 폴더 이름, Youtube 영상 URL과 자막 언어(한국어 : ‘ko’, 일본어 : ‘ja’)를 지정해줍니다.

- download_caption()를 통해서 각각 데이터셋 폴더에 자막 파일들을 다운로드 합니다.
- alignment.json 파일에 한국어와 일본어 자막이 각각 생성된 것을 확인 할 수 있습니다.
(한국어, 일본어) 스피치 데이터셋 생성 실습 [ Audio Download Step ]
Korean_VCTUBE.download_audio()Japanese_VCTUBE.download_audio()

- download_audio() 함수를 통해 해당 Youtube 영상에 대한 오디오 파일이 각각 다운로드 된 것을 확인할 수 있습니다.
(한국어, 일본어) 스피치 데이터셋 생성 실습 [ Caption Download Step ]
Korean_VCTUBE.download_captions()
Japanese_VCTUBE.download_captions()
- download_caption()를 통해서 각각 데이터셋 폴더에 자막 파일들을 다운로드 합니다.
- alignment.json 파일에 한국어와 일본어 자막이 각각 생성된 것을 확인 할 수 있습니다.
(한국어, 일본어) 스피치 데이터셋 생성 실습 [ Audio Split Step ]
Korean_VCTUBE.audio_split()
Japanese_VCTUBE.audio_split()
- audio_split()함수를 통해 wavs폴더에 자막에 해당하는 오디오 파일이 생성된 것을 확인할 수 있습니다.

