

import pandas as pdimport seaborn as snsimport numpy as npfrom sklearn.feature_extraction.text import CountVectorizer- from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import classification_reportfrom sklearn.model_selection import train_test_splitfrom nltk.stem.snowball import EnglishStemmerfrom imblearn.over_sampling import SMOTEfrom sklearn.metrics import confusion_matriximport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npdf = pd.read_csv("snopes.tsv", sep="\t") # load dataprint(df.shape) # how many articles?
판다스 라이브러리의 read_csv 함수를 사용하여 데이터 셋을 로드하고 데이터의 크기를 확인하기 위해서 shape를 프린트해 봅니다.
튜토리얼에서 사용하는 데이터 셋의 경우 총 12410 row가 있으며 각 row는 16개의 피처를 가집니다.
데이터명 | 설명 |
게시글 번호 | 기사의 고유 번호 |
제목 | 기사의 제목 |
URL | 기사의 링크 |
요약글 | 기사의 내용에 대한 요약글 |
발행일 | 기사 발행일 |
수정일 | 기사 수정일 |
카테고리 | 루머의 주제에 대한 카테고리 |
클레임(Claim) | 검증하는 루머의 내용. 하나의 문장으로 표현. |
루머 평가(Veracity) | 검증한 루머에 대한 평가 결과. 참, 거짓 외에도 대부분 참, 대부분 거짓 등의 값을 가질 수 있음. |
정보처 | 루머를 검증하는 데 사용한 정보 출처 |
태그 | 루머의 주제를 나타낼 수 있는 키워드 |
자세한 데이터 구조는 다음과 같습니다.
데이터 셋은 온라인 팩트체킹 서비스인 Snopes (https://snopes.com) 에서 수집되었습니다.
본 튜토리얼에서는 루머의 내용을 한 문장으로 표현한 클레임(Claim) 과 루머에 대한 평가(Veracity) 만을 다룰 예정입니다.
df.head()
df.head 함수는 판다스 데이터프레임 내부에서 앞선 5개의 데이터들을 보여줍니다.
df = df[(df["veracity"]=="true")|(df["veracity"]=="false")] # veracity true or falsedf.shape
앞선 데이터를 확인하면 veracity (루머의 평가) 부분이 NaN, false, true가 섞여있는 것을 확인할 수 있습니다.
Fake News Classification 문제를 조금 더 단순화하기 위해서 이번 튜토리얼에서는 True 혹은 False인 뉴스만 다룰 것이기 때문에 위와 같이 코드를 작성하여 실행해줍니다.
True와 False로만 구성된 데이터 셋은 총 6266 개의 뉴스를 가지고 있음을 확인할 수 있습니다.
이후, df.head()로 한번 더 확인해보면 veracity가 NaN인 row가 없어졌음을 확인할 수 있습니다.
df['year'] = df.published_date.apply(lambda x: int(x.split(" ")[0].split("-")[0])) # create year columndf['month'] = df.published_date.apply(lambda x: int(x.split(" ")[0].split("-")[1])) # create month columnprint(df.head())
추후에 분석하기 위해 published_date 에서 year와 month를 따로 저장하는 작업을 해줍니다.
새로운 year, month 피처는 월별, 연도별 뉴스의 수를 분석할 때 사용합니다.
마지막으로 df.head를 통해 데이터를 확인해줍니다.
데이터프레임의 끝에 year와 month가 생긴 것을 확인할 수 있습니다.
categories = df.category.value_counts()categories = pd.DataFrame(categories)categories = categories.reset_index()categories.columns = ['category', 'count']- categories.tail()
지금부터는 본격적인 모델 학습에 앞서서 Fake News 데이터를 알아보겠습니다.
우선 어떠한 카테고리별 뉴스의 분포를 확인하기 위해서 다음과 같이 카테고리별 뉴스의 개수를 dataframe으로 만듭니다.
def plot_bargraph(x, y, data, ax, title, ylim, rotation, ylabel="", xlabel=""):sns.barplot(x=x, y=y, data=data, ax=ax)ax.set_title(title, fontsize=16)for tick in ax.get_xticklabels():- tick.set_rotation(rotation)
ax.set_ylim(0, ylim)ax.set_ylabel(ylabel, fontsize=14)ax.set_xlabel(xlabel, fontsize=14)ax.tick_params(labelsize=13)
다음은 플롯을 그리기 위한 함수입니다.
Seaborn 라이브러리를 활용했습니다.
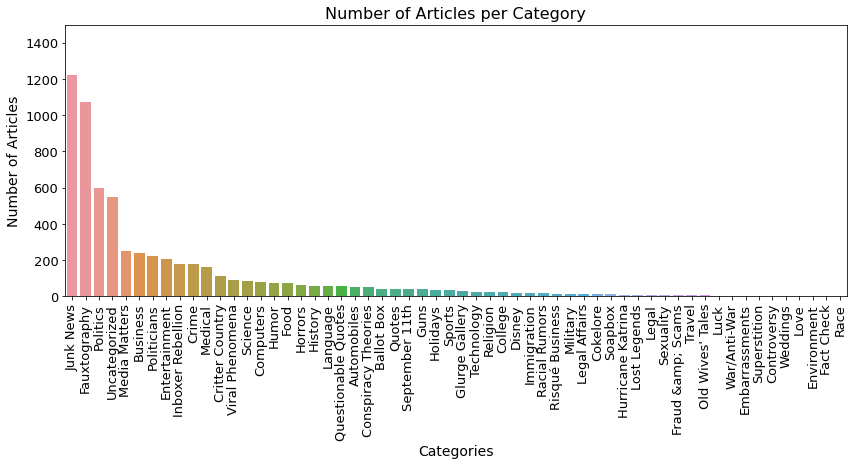
# plot categoriesfig, ax = plt.subplots()fig.set_size_inches(14,5)- plot_bargraph("category", "count", categories, ax, "Number of Articles per Category", 1500, 90, "Number of Articles", "Categories")
플롯을 그려보니 Junk News가 가장 많은 뉴스의 양을 차지하는 것을 확인할 수 있고, Politics도 있는 것을 확인할 수 있습니다.
이는 정치분야에서 가장 Fake News가 많이 나오기 때문인 것 같습니다.
또한, 현재 사용하고 있는 Snopes 기반의 Fake News 데이터 셋은 정치 분야 외에도 꽤 다양한 분야의 뉴스를 포함하고 있음을 확인할 수 있습니다.
years = df.groupby('year')['id'].count()years = pd.DataFrame(years)years = years.reset_index()years.columns = ['year', 'count']- years.tail()
다음은 연도별 뉴스의 개수를 확인하기 위해 dataframe을 생성하는 과정입니다.
fig, ax = plt.subplots()fig.set_size_inches(8,5)plot_bargraph("year", "count", years[years['year']>=2009], ax, "Number of Articles per Year", 2000, 0, "Number of Articles", "Year")
시각화를 진행해보면 미국 대선이 있었던 2016년에 가장 많은 뉴스가 있음을 확인할 수 있습니다.
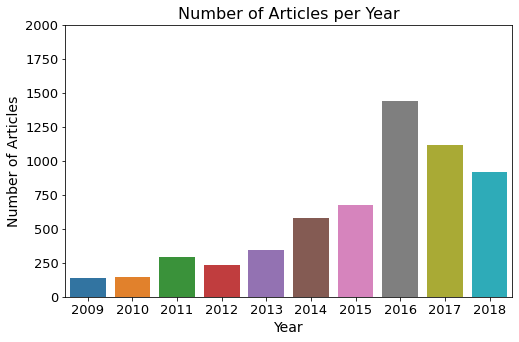 n
n
months = df[df['year'] == 2016].groupby('month')['id'].count()months = pd.DataFrame(months)months = months.reset_index()months.columns = ['month', 'count']- months.head()
다음은 월별 기사 수를 알아보고자 합니다.
이전 플롯에서 2016년에 가장 많은 기사가 제보 되었음을 확인하였으므로, 2016년을 특정하여 월별 기사 수를 확인해보겠습니다.
fig, ax = plt.subplots()fig.set_size_inches(8,4)plot_bargraph("month", "count", months, ax, "Number of Articles per Month", 200, 0, "Number of Articles", "Months")
플롯을 확인해보면 6월을 기준으로 상반기보다는 하반기에 뉴스가 많은 것을 확인할 수 있습니다.
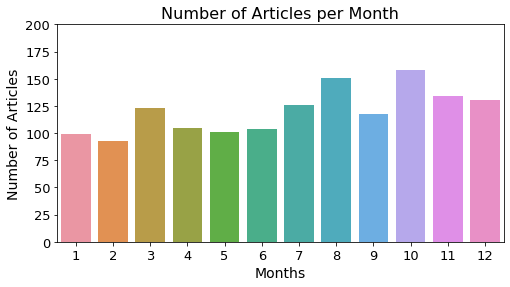
fake_news = df[["claim", "veracity"]]fake_news = fake_news.dropna()
이제 기본적인 분석은 완료했고, 실제로 모델을 학습시켜 claim만을 가지고 veracity를 예측할 것 입니다.
그러기 위해서 기존의 dataframe을 조금 더 간단한 형태로 다음과 같이 변환해줍니다.
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(fake_news['claim'], fake_news['veracity'],random_state = 1, test_size=0.3)
Train 데이터는 학습 중에만 사용되며 Test 데이터는 학습 도중에는 모델이 알 수 없습니다.
이렇게 학습을 하고 평가를 해야만 모델이 real data를 만났을 때 어느 정도의 성능을 보일지에 대한 정확한 평가가 가능합니다.
튜토리얼에서는 Test 데이터 셋의 비율을 30%로 진행했습니다.
stemmer = EnglishStemmer()analyzer = CountVectorizer(min_df = 0.5, ngram_range = (1, 3), stop_words='english').build_analyzer()def stemmed_words(doc):- return (stemmer.stem(w) for w in analyzer(doc))
vect = CountVectorizer(analyzer=stemmed_words).fit(X_train)X_train_vectorized = vect.transform(X_train)len(vect.get_feature_names())
우리가 가지고 있는 데이터는 자연어 형태 입니다. 모델을 학습시키기 위해서는 수치적인 형태로 변환해주어야 합니다.
이때 모델이 조금 더 학습을 하기 쉽도록 단어의 어간을 추출하는 작업도 같이 진행하면 좋습니다.
*Stemming은 어간을 추출하는 작업입니다. Stemming에 대한 자세한 내용은 다음의 사이트에서 확인할 수 있습니다. (https://wikidocs.net/21707)
# without smotemodel = RidgeClassifier(class_weight='balanced')model.fit(X_train_vectorized, y_train)predictions = model.predict(vect.transform(X_test))- print(classification_report(y_test, predictions))
이제 모델을 학습시키고 Test 셋을 통해서 평가를 진행합니다.
본 튜토리얼에서는 따로 모델의 파라미터를 튜닝하지 않고 class_weight만 balanced로 두었습니다.
그리고 최종적으로 classification_report 함수를 통해 모델의 성능을 확인했습니다.
precision recall f1-score supportfalse 0.81 0.66 0.72 1515true 0.18 0.33 0.24 356accuracy 0.59 1871macro avg 0.50 0.49 0.48 1871weighted avg 0.69 0.59 0.63 1871
하지만, 클래스 불균형으로 인해 모델의 성능이 그렇게 높지 않습니다.
오버샘플링을 진행해보도록 하겠습니다.
X_train_vectorized_smote, y_train_smote = SMOTE(random_state=1).fit_sample(X_train_vectorized, y_train) # over-sampling
오버샘플링은 클래스의 불균형이 있을 경우 소수 클래스에 대해서 데이터를 생성해주는 작업입니다.
현재 데이터 분포와 유사한 데이터 포인터들을 생성해서 모델학습에 도움을 줍니다.
단, 언더/오버샘플링은 반드시 Train 데이터에만 적용합니다!
본 튜토리얼에서는 오버샘플링 기법 중 SMOTE를 사용했습니다.
# with smotemodel = RidgeClassifier(class_weight='balanced')model.fit(X_train_vectorized_smote, y_train_smote)predictions = model.predict(vect.transform(X_test))- print(classification_report(y_test, predictions))
precision recall f1-score supportfalse 0.84 0.77 0.80 1515true 0.27 0.35 0.30 356accuracy 0.69 1871macro avg 0.55 0.56 0.55 1871weighted avg 0.73 0.69 0.71 1871
SMOTE를 적용하니 성능이 조금 향상되었습니다.
여전히 성능이 낮기는 하지만, 모델 셀렉션, 파라미터 튜닝 과정을 거치거나 다른 딥러닝 모델을 활용하면 성능이 올라갈 것이라 기대합니다.
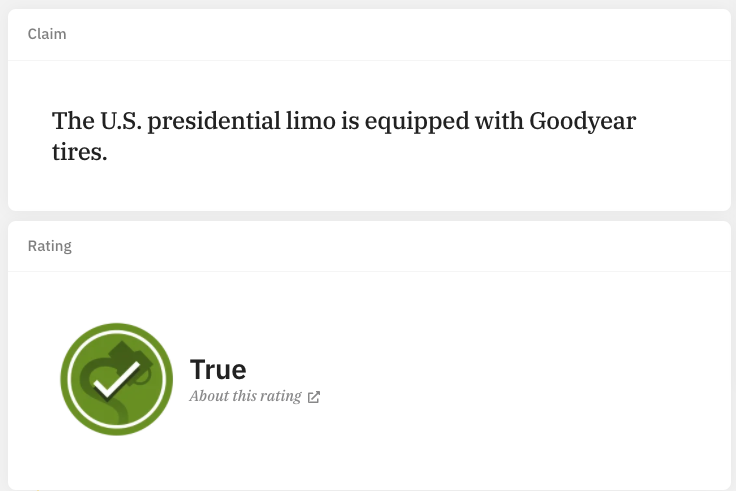
마지막으로 실제 snopes.com 사이트에 있는 claim에 대해서 예측을 진행해보도록 하겠습니다.
문장 하나를 벡터화 시킨 다음 학습된 모델에 인풋으로 넣어주면 다음과 같이 예측값을 반환해줍니다.
그 결과, 정답과 일치하는 TRUE가 나왔습니다.
def prediction(sentence):return(model.predict(vect.transform([sentence])))prediction("The U.S. presidential limo is equipped with Goodyear tires.")[0]
- 'true'

