
인공지능 기반 코로나 관련 가짜뉴스 팩트체킹 모델 설계 튜토리얼
- 등록자 이다은
- 등록일 2020-12-03 10:33 (2021-09-15 11:31)
- 조회수 5705
 0
0 0
0
Fake News란 각종 SNS를 통해서 빠르게 전파되고, 확대 재생산 되는 ‘가짜 뉴스’를 말합니다.
코로나 19 관련 가짜뉴스는 다른 가짜뉴스에 비해 사람들의 불안감을 더욱 증폭시켜 막대한 사회적 혼란을 주고 있는데요.

위에 보이는 가짜뉴스들은 코로나 기간 중에 관련 유튜브 비디오를 많이 만들어낸 가짜뉴스입니다.
이번 튜토리얼에서는 이렇게 문제가 되고 있는 코로나19와 관련된 가짜뉴스를 찾아내는 인공지능 팩트체킹 모델을 만들어 보겠습니다.
가짜뉴스 데이터셋은 SNU FactCheck 서울대학교 언론정보연구소(https://factcheck.snu.ac.kr/)에서 수집한 데이터들을 사용할 것입니다.
아래의 코드를 치면, 데이터셋의 형태와 대략적인 내용을 확인해보실 수 있습니다.
import pandas as pd
# 유튜브 상위 조회수 코로나 관련 가짜뉴스
df_FakeNews = pd.read_csv('fake_new_ex.csv')
df_FakeNews.head(5)추가로 이번 튜토리얼에서는 가짜뉴스를 더 잘 선별할 수 있는 모델을 만들기 위해, 개체명 데이터와 유튜브 비디오 정보를 함께 사용했습니다.
다음의 코드를 통해서 실험에 사용될 데이터들을 확인해보겠습니다.
df_train = pd.read_csv('train2.csv',sep='\t')
df_test = pd.read_csv('test1.csv',sep='\t')
df_test.head()위에 보이시는 ‘entity’ 컬럼은 개체명 정보를 뜻하는데요, SKTBrain의 KoBERT와 CRF로 만든 한국어 객체명인식기를 이용하여 뉴스 기사에서 추출한 것입니다.
유튜브 비디오 정보는 뉴스 기사에서 자주 등장한 키워드로 검색된 유튜브 동영상에서 추출하였는데요, 유튜브 정보 추출은 Youtbe API를 활용하였습니다.
print(len(df_train))
print(len(df_test))전체 데이터의 양은 train data 2210개, test data 184개 인 것을 확인할 수 있습니다.
이제 본격적으로 가짜뉴스를 판별하는 모델을 만들어보겠습니다. 튜토리얼에서 사용할 모델은 BERT (Bidirectional Encoder Representations from Transformer)입니다.
위에서 불러온 3개의 데이터(뉴스기사 텍스트, Entity, Youtube 텍스트)를 이용해 구성을 달리해서 다양한 모델을 실험해 볼 수 있습니다.
이번 실험에서는 뉴스 기사 + Entity + Youtube 정보를 모두 활용한 모델로 실험을 진행해볼 것입니다.
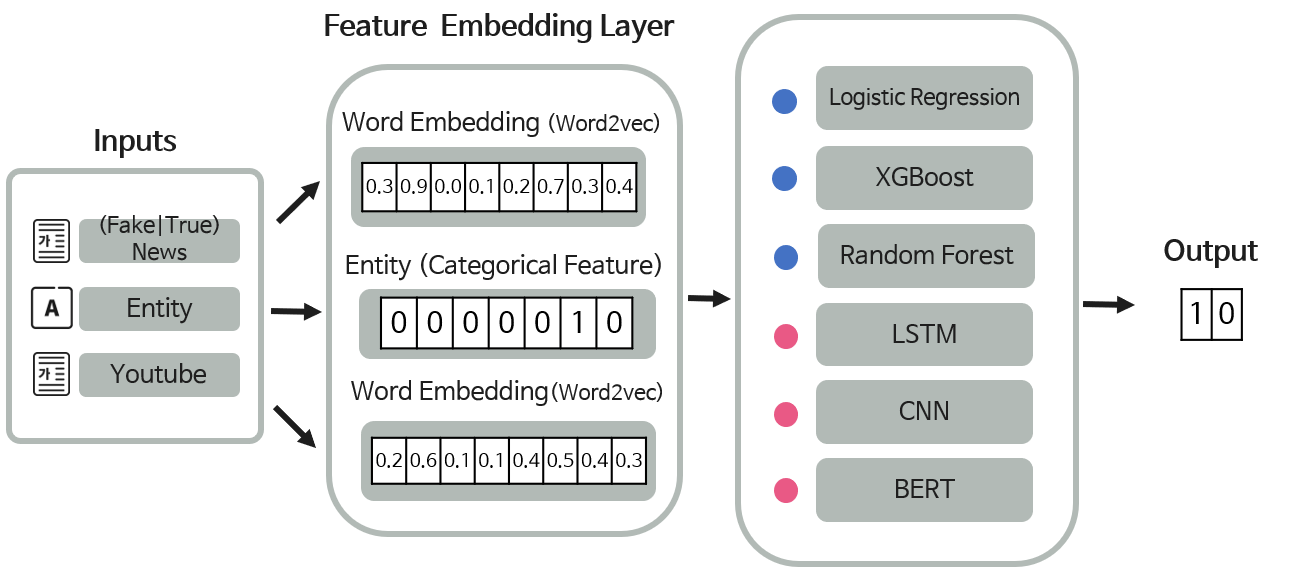
먼저 위 그림을 통해서 모델의 작동방식을 간략하게 설명해보겠습니다.
우선, 세 종류의 입력값을 받아 각각을 사전 학습된 BERT의 토크나이저를 통해서 임베딩 작업을 수행하고, 여기서 나온 벡터값을 이용하여 분류 레이어를 거쳐서, 입력으로 받은 뉴스기사가 실제로 가짜뉴스인지 아닌지 판별해줍니다.
이제 작동방식에 대해 이해해 보았으니, 코드로 직접 구현해보겠습니다. 먼저 모델 설계에 필요한 패키지를 불러옵니다.
# reference:
# https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing#scrollTo=qu1QkSZsHo8x
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import pandas as pd
import numpy as np
import os
from pprint import pprint
import pickle
import torch
from torch.utils.data import Dataset, DataLoader, TensorDataset
from torch.optim.lr_scheduler import ExponentialLR
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
import torch.nn.functional as F
from pytorch_lightning import LightningModule, Trainer, seed_everything
from transformers import BertModel, BertTokenizer, AdamW, BertForSequenceClassification
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
from pytorch_lightning.loggers import TensorBoardLogger
from pathlib import Path
from collections import Counter
import random
# clean text:
import re
import emoji
from soynlp.normalizer import repeat_normalize
from soynlp.normalizer import *
from collections import Counter
emojis = ''.join(emoji.UNICODE_EMOJI.keys())
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-힣{emojis}]+')
username_pattern = re.compile(
r"(?<=^|(?<=[^a-zA-Z0-9-_\.]))@([A-Za-z]+[A-Za-z0-9-_]+)")
url_pattern = re.compile(
r"[-a-zA-Z0-9@:%_\+.~#?&//=]{2,256}\.[a-z]{2,4}\b(\/[-a-zA-Z0-9@:%_\+.~#?&//=]*)?")다음으로 모델에서 사용될 기본 인자들을 설정해주겠습니다. 배치사이즈 16, 에폭 4, 옵티마이저는 AdamW를 사용하겠습니다.
‘train_data_path’, ‘val_data_path’에는 실험에 사용될 데이터가 있는 경로를 지정해주고, ‘feature_mode’에는 실험에 어떤 feature가 쓰일지에 따라 다양하게 설정해볼 수 있습니다.
def clean(x):x = pattern.sub(' ', x)x = username_pattern.sub('', x)x = url_pattern.sub('', x)x = repeat_normalize(x, num_repeats=2)x = x.strip()return xclass Arg:random_seed: int = 2020 # Random Seedpretrained_model = "beomi/kcbert-base" # Transformers PLM namepretrained_tokenizer = "beomi/kcbert-base" # Optional, Transformers Tokenizer Name. Overrides `pretrained_model`cache_dir = './models/cache'train_data_path = 'train2.csv'val_data_path = 'test1.csv'feature_mode = 'w' #w_s, w_u, w_u_slog_dir = './models/checkpoints'log_name = 'kcbert-base-stressor-binary-clf'version = 1batch_size: int = 32 # Optional, Train/Eval Batch Size. Overrides `auto_batch_size`lr: float = 5e-5 # Starting Learning Rate, BERT paper settingepochs: int = 4 # Max Epochs, BERT paper setting [3,4,5]max_length: int = 200 # Max Length input sizereport_cycle: int = 30 # Report (Train Metrics) Cyclecpu_workers: int = os.cpu_count() # Multi cpu workerstest_mode: bool = False # Test Mode enables `fast_dev_run`optimizer: str = 'AdamW' # AdamW vs AdamPlr_scheduler: str = 'exp' # ExponentialLR vs CosineAnnealingWarmRestartsfp16: bool = False # Enable train on FP16hidden_dropout_prob = 0.1 # BERT paper settinghidden_size = 768 # BERT-base: 768, BERT-large: 1024, BERT paper setting
모델에 사용될 기능을 정의하는 init() 함수와 init() 함수에서 정의한 기능들을 실행하는 forward() 함수를 정의해 줍니다.
class Model(LightningModule):def __init__(self, options):super().__init__()# config:self.args = optionsself.batch_size = self.args.batch_size# meta data:self.epochs_index = 0self.label_cols = 'label' # ['null','academic','entertainment','family','health','money','political','social','work','other']self.num_labels = 2# modules:self.tokenizer = BertTokenizer.from_pretrained(self.args.pretrained_tokenizer, cache_dir=self.args.cache_dir)self.bert_data = BertModel.from_pretrained(self.args.pretrained_model, cache_dir=self.args.cache_dir)self.bert_ent = BertModel.from_pretrained(self.args.pretrained_model, cache_dir=self.args.cache_dir)self.bert_utu = BertModel.from_pretrained(self.args.pretrained_model, cache_dir=self.args.cache_dir)#self.fc_utu = nn.Linear(200, self.args.hidden_size)if self.args.feature_mode == 'w': num_feature = 1elif self.args.feature_mode == 'w_u': num_feature = 2elif self.args.feature_mode == 'w_s': num_feature = 2elif self.args.feature_mode == 'w_s_u': num_feature = 3self.fc1 = nn.Linear(self.args.hidden_size*num_feature, self.args.hidden_size)self.dropout = nn.Dropout(self.args.hidden_dropout_prob)self.classifier = nn.Linear(self.args.hidden_size, self.num_labels)def forward(self,data, entity, utube, **kwargs):outputs_data = self.bert_data(input_ids =data, **kwargs) # return: last_hidden_state, pooler_output, hidden_states, attentionsoutput = outputs_data[1]if self.args.feature_mode == 'w_u':outputs_utu = self.bert_utu(input_ids =utube, **kwargs)pooled_outputs_utu = outputs_utu[1]output = torch.cat([output, pooled_outputs_utu], dim=1)elif self.args.feature_mode == 'w_s':outputs_ent = self.bert_ent(input_ids =entity, **kwargs) # return: last_hidden_state, pooler_output, hidden_states, attentionspooled_outputs_ent = outputs_ent[1]output = torch.cat([output, pooled_outputs_ent], dim=1)elif self.args.feature_mode == 'w_s_u':outputs_utu = self.bert_utu(input_ids =utube, **kwargs)outputs_ent = self.bert_ent(input_ids =entity, **kwargs) # return: last_hidden_state, pooler_output, hidden_states, attentionspooled_outputs_utu = outputs_utu[1]pooled_outputs_ent = outputs_ent[1]output = torch.cat([output, pooled_outputs_utu,pooled_outputs_ent], dim=1)pooled_output = self.dropout(self.fc1(output))logits = self.classifier(pooled_output)return logits
configure_optimizers() 함수에서 옵티마이저를 정의하고, preporcess_dataframe() 함수에서 입력으로 받은 CSV 파일을 정제해주도록 합니다.
# class Model(LightningModule): 계속이어짐
def configure_optimizers(self):if self.args.optimizer == 'AdamW':optimizer = AdamW(self.parameters(), lr=self.args.lr)elif self.args.optimizer == 'AdamP':from adamp import AdamPoptimizer = AdamP(self.parameters(), lr=self.args.lr)else:raise NotImplementedError('Only AdamW and AdamP is Supported!')if self.args.lr_scheduler == 'cos':scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=1, T_mult=2)elif self.args.lr_scheduler == 'exp':scheduler = ExponentialLR(optimizer, gamma=0.5)else:raise NotImplementedError('Only cos and exp lr scheduler is Supported!')return {'optimizer': optimizer,'scheduler': scheduler,}def preprocess_dataframe(self, df,col_name):df[col_name] = df[col_name].map(lambda x: self.tokenizer.encode(str(x),pad_to_max_length = True,max_length=self.args.max_length,truncation=True,))return df
dataloader() 함수에서는 배치사이즈 단위로 모델에 입력값을 넣어줄 수 있도록 데이터로더를 정의합니다.
# class Model(LightningModule): 계속 이어짐 def train_dataloader(self):
df = pd.read_csv(self.args.train_data_path, sep='\t',encoding='utf-8')
df = self.preprocess_dataframe(df,'token')
df = self.preprocess_dataframe(df,'entity')
df = self.preprocess_dataframe(df,'youtube')
pprint(f"Train Size: {len(df)}")
dataset = TensorDataset(
torch.tensor(df['token'].to_list(), dtype=torch.long),
torch.tensor(df['entity'].to_list(), dtype=torch.long),
torch.tensor(df['token'].to_list(), dtype=torch.long),
torch.tensor(df[self.label_cols].to_list(), dtype=torch.long),
)
return DataLoader(
dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=self.args.cpu_workers,
)
def val_dataloader(self):
df = pd.read_csv(self.args.val_data_path, sep='\t',encoding='utf-8')
df = self.preprocess_dataframe(df,'token')
df = self.preprocess_dataframe(df,'entity')
df = self.preprocess_dataframe(df,'youtube')
pprint(f"Val Size: {len(df)}")
dataset = TensorDataset(
torch.tensor(df['token'].to_list(), dtype=torch.long),
torch.tensor(df['entity'].to_list(), dtype=torch.long),
torch.tensor(df['token'].to_list(), dtype=torch.long),
torch.tensor(df[self.label_cols].to_list(), dtype=torch.long),
)
return DataLoader(
dataset,
batch_size=self.batch_size,
shuffle=False,
num_workers=self.args.cpu_workers,
)training_step(), validation_step()은 모델에 입력값을 넣어주고, 오차값을 구해주는 함수입니다.
# class Model(LightningModule): 계속 이어짐 def training_step(self, batch, batch_idx):
data, entity, utube, labels = batch
logits = self(data, entity, utube)
loss = None
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return {'loss': loss}
def validation_step(self, batch, batch_idx):
data, entity, utube, labels = batch
logits = self(data, entity, utube)
loss = None
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
preds = logits.argmax(dim=-1)
# loss, logits = self(input_ids=data, labels=labels)
# preds = logits.argmax(dim=-1)
y_true = list(labels.cpu().numpy())
y_pred = list(preds.cpu().numpy())
return {
'loss': loss,
'y_true': y_true,
'y_pred': y_pred,
}마지막으로 validation_epoch_end() 함수를 통해서 모델을 학습시킨 후 검증 과정을 거쳐 그 결과값을 출력할 수 있도록 합니다.
# class Model(LightningModule): 계속 이어짐 def validation_epoch_end(self, outputs):
loss = torch.tensor(0, dtype=torch.float)
for i in outputs:
loss += i['loss'].cpu().detach()
_loss = loss / len(outputs)
loss = float(_loss)
y_true = []
y_pred = []
for i in outputs:
y_true += i['y_true']
y_pred += i['y_pred']
y_pred = np.asanyarray(y_pred)
y_true = np.asanyarray(y_true)
# save:
if self.epochs_index == self.args.epochs -1:
pickle.dump(y_pred, open(os.path.join(self.args.log_dir, self.args.log_name, f'version_{self.logger.version}',
f'pred_{self.label_cols}_epoch_{self.epochs_index}.p'), 'wb'))
pickle.dump(y_true, open(os.path.join(self.args.log_dir, self.args.log_name, f'version_{self.logger.version}',
f'true_{self.label_cols}_epoch_{self.epochs_index}.p'), 'wb'))
self.epochs_index += 1
# Acc, Precision, Recall, F1
metrics = [
metric(y_true=y_true, y_pred=y_pred)
for metric in
(accuracy_score, precision_score, recall_score, f1_score)
]
tensorboard_logs = {
'val_loss': loss,
'val_acc': metrics[0],
'val_precision': metrics[1],
'val_recall': metrics[2],
'val_f1': metrics[3],
}
print()
pprint(tensorboard_logs)
return {'loss': _loss, 'log': tensorboard_logs}앞에서 설계한 모델이 차례로 수행될 수 있도록 main() 함수를 정의하여, 실제로 실행시켜보겠습니다.
def main():
args = Arg()
print("Using PyTorch Ver", torch.__version__)
print("Fix Seed:", args.random_seed)
seed_everything(args.random_seed)
model = Model(args)
logger = TensorBoardLogger(
save_dir=args.log_dir,
version=args.version,
name=args.log_name
)
print(":: Start Training ::")
trainer = Trainer(
logger = logger,
max_epochs=args.epochs,
fast_dev_run=args.test_mode,
num_sanity_val_steps=None if args.test_mode else 0,
#auto_scale_batch_size=args.auto_batch_size,
deterministic=True, # ensure full reproducibility from run to run you need to set seeds for pseudo-random generators,
# For GPU Setup
gpus=[0] if torch.cuda.is_available() else None,
precision=16 if args.fp16 else 32
)
trainer.fit(model)실제 실행을 시켜 결과값을 출력합니다.
main()

