


한국의 자살률은 세계적으로도 높은 수준입니다.
아래의 그래프는 2019년 OECD 가입 국가의 자살률 을 나타냅니다. 대한민국은 자살률 24.6로 1위로 기록된 것을 확인할 수 있습니다.
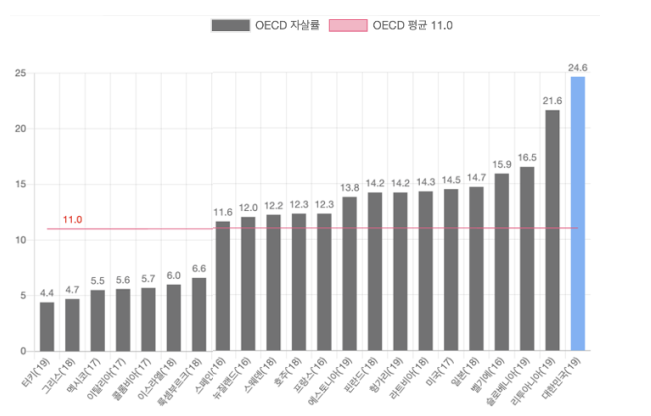
[출처] 한국생명존중희망재단, 2019년 인구 10만 명당 자살사망자 (자살사망률)
자살은 정신질환 문제와 밀접한 관계가 있습니다. 그리고 이를 제때 치료받지 못해 자살로 이르는 사람이 많습니다.
보통 사람들은 자신에게 어떠한 정신질환 문제가 있다는 것을 느끼더라도, 정신질환에 대한 사회의 부정적 시선으로 인해 자신의 상황을 알리고 주위에 도움을 구하는 것을 어려워합니다.
정신보건 서비스 이용도 마찬가지입니다. 정신보건 서비스에 대한 심리적 또는 경제적 장벽으로 인해, 이를 선뜻 이용하기도 쉽지 않습니다.
그렇다면, 인공지능을 통해 자신에게 내재되어 있는 정신질환을 확인해볼 수 있다면 어떨까요?
익명성 과 접근성은 인공지능의 장점이라고 할 수 있습니다. 인공지능으로 만든 정신질환 관련 모델이 있다면, 사람들은 이를 통해 익명으로 간편하게 자신의 정신 상태를 점검해볼 수 있을 것입니다.
따라서, 이 튜토리얼에서는 정신질환 관련 데이터를 이용해, 다양한 NLP 기반의 응용 모델을 만들어보 겠습니다.
또, 마지막에는 만든 모델들을 활용하여 설계한 정신질환 QA 시스템을 소개해드리겠습니다.
정신질환 데이터는 네이버의 지식 공유 플랫폼인 지식iN에서 수집할 것입니다.
이를 위해 네이버 오픈 API를 활용합니다. 아래 링크를 클릭하시면, 다음과 같은 화면을 볼 수 있습니다.
이곳에 안내되어 있는 절차를 거쳐 Client ID와 Client Secret 값을 발급 받으실 수 있습니다.
본격적인 데이터 수집을 위해, 필요한 패키지를 불러옵니다.
import pandas as pdimport numpy as npimport osimport sysimport urllib.requestfrom urllib.request import urlopenfrom bs4 import BeautifulSoupimport datetimeimport csvimport requestsfrom collections import Counter
아래와 같이, 발급받은 값을 Client ID와 Client Secret 변수에 입력해주세요.
client_id = "CLIENT-ID"client_secret = "CLIENT-SECRET"encText = urllib.parse.quote("우울증") #검색 키워드url = "https://openapi.naver.com/v1/search/kin?query=" + encText +"&display=10" #json 결과request = urllib.request.Request(url)request.add_header("X-Naver-Client-Id",client_id)request.add_header("X-Naver-Client-Secret",client_secret)response = urllib.request.urlopen(request)rescode = response.getcode()if(rescode==200):response_body = response.read()else:print("Error Code:" + rescode)
encText는 검색 키워드를 지정하는 것으로, 이를 통해 지식인 데이터 중에서 어떤 검색어의 결과를 수집할 것인지 정할 수 있습니다.
예시에서는 “우울증”의 검색 결과를 확인하고자 합니다. 이외에도 수집하고 싶은 다양한 정신질환 키워드를 입력할 수 있습니다.
url 변수에 있는 몇 가지 인자를 통해 검색결과를 조정할 수 있습니다.
예시에서 사용된 display는 몇 개의 데이터를 수집할 것인지에 대한 값입니다. 지금은 예를 위해 10개만 수집하도록 되어 있습니다.
이외에도 시작 지점을 의미하는 start 인자 등 다양하게 활용 가능한 인자들이 제공되고 있으니 자세한 정보는 공식 페이지를 참고하시면 되겠습니다.
아래 코드를 통해 수집된 데이터를 확인할 수 있습니다.
글의 제목(title), 링크(link), 본문의 일부(description)가 나타나 있습니다.
response_body.decode('utf-8').split('{')[2].split('\n')
글의 전문과 답변을 수집하기 위하여 링크를 데이터프레임 형태로 따로 저장합니다.
split = response_body.decode('utf-8').split('{')links = []for i in range(2, len(split)):links.append(split[i].split('\n')[2][9:-2])df = pd.DataFrame(links)
df.columns = ['url']df
이후 이 링크의 주소를 바탕으로, 데이터를 크롤링합니다.
하나의 질문에 여러 개의 답변이 달릴 수 있는 점을 고려하여 수집이 진행됩니다.
# 결과를 저장할 리스트titles = []questions = []answers = []qa_urls = []failed_urls = []a_number = []for i, url in enumerate(df.url):print("---------------------------",i,"---------------------------")response = requests.get(url)print(url)# candidate answer listscandid_answers = []if response.status_code == 200:html = response.textsoup = BeautifulSoup(html, 'html.parser')# title and questiontry:title = soup.select_one("#content > div.question-content > div > div.c-heading._questionContentsArea.c-heading--default-old > div.c-heading__title > div.c-heading__title-inner > div.title").get_text().strip()question = soup.select_one("#content > div.question-content > div > div.c-heading._questionContentsArea.c-heading--default-old > div.c-heading__content").get_text().strip()except:try:title = soup.select_one("#content > div.question-content > div > div.c-heading._questionContentsArea.c-heading--multiple-old > div.c-heading__title > div.c-heading__title-inner > div.title").get_text().strip()question = soup.select_one("#content > div.question-content > div > div.c-heading._questionContentsArea.c-heading--multiple-old > div.c-heading__content").get_text().strip()except:try:title = soup.select_one("#content > div.question-content > div > div.c-heading._questionContentsArea.c-heading--default > div.c-heading__title > div.c-heading__title-inner > div.title").get_text().strip()question = '제목과 내용 동일'except:try:title = soup.select_one("#content > div.question-content > div > div.c-heading._questionContentsArea.c-heading--multiple > div.c-heading__title > div.c-heading__title-inner > div.title").get_text().strip()question = '제목과 내용 동일'except:failed_urls.append(df['url'][i])continuefor j in range(1,15):try:temp = soup.select_one('#answer_' + str(j)).get_text().strip().split('\n\n\n\n\n\n')[2]temp = ' '.join(temp.split('\n\n')[:-1])temp = temp.replace('위 답변은 답변작성자가 경험과 지식을 바탕으로 작성한 내용입니다. 포인트로 감사할 때 참고해주세요.', ' ')temp = temp.replace('본 답변은 참고 용도로만 활용 가능하며 정확한 정보는 관련기관에서 확인해보시기 바랍니다.', ' ')temp = temp.replace('알아두세요', ' ')if temp != '':titles.append(title)questions.append(question)answers.append(temp)qa_urls.append(url)except:breakelse:print(response.status_code)# Check saved dataprint(len(titles))print(len(questions))print(len(answers))print(len(qa_urls))print(len(failed_urls))
수집된 데이터를 데이터 프레임 형태로 저장합니다.
# Convert List to DataFrame and Savekin = pd.DataFrame({'title' : titles,'question' : questions,'answer' : answers,'url' : qa_urls})kin
저희 연구팀은 위와 같은 과정으로 "우울증(우울장애)", "불안장애", "섭식장애" 세 가지 정신질환 데이터셋을 구축하였습니다.
이후 수집한 데이터셋을 직접 확인하면서 '의료 전문가가 답변한 글'만 필터링 하였습니다.
최종 데이터는 2,178개입니다. (이 데이터는 제공하지 않습니다.)

각 질환별 데이터 개수는 아래 코드로 확인할 수 있습니다.
- Counter(data['disorder'])
[Result] Counter({'우울장애': 1013, '섭식장애': 544, '불안장애': 621})
데이터를 수집한 이후에는, 질문/답변을 바탕으로 어노테이션을 진행하였습니다.
질문글에서는 인삿말, 끝맺음말, 내공 제시 문구 등의 불필요한 내용을 제외한, 증상이 드러난 부분만 추출하였습니다.
의료전문가 답변글에서는, 답변이 주로 <진단>에 해당되는 부분, 이를 의심할 수 있는 질문자의 증상, 즉 <진단에 대한 근거>, 그리고 <해결책> 순서로 구성된다는 점을 고려하여,
이 세 가지를 각각 분리하여 저장하였습니다.

NLP 기반 응용 모델은 라벨링된 데이터셋을 바탕으로 진행됩니다.
데이터는 아래 링크에서 다운받으실 수 있습니다.
다운로드 한 데이터를 불러옵니다.
data = pd.read_csv("data/kin_data.csv")data
이 튜토리얼에서는 총 두 가지 모델을 만들어 볼 것입니다.
첫 번째는 정신질환 예측 모델로, 이는 입력 데이터를 우울장애, 불안장애, 섭식장에 세 가지 질환 중 하나로 예측하는 모델입니다.
두 번째는 증상 추출 알고리즘으로, 처음에 수집했던 답변글 중에서 <진단에 대한 근거>를 제시하는 부분처럼 만들어 볼 예정입니다.
먼저, 정신질환 예측 모델을 구축해보겠습니다.
튜토리얼에서 사용할 모델은 KcBERT입니다. KcBERT는 BERT(Bidirectional Encoder Representations from Transformer)를 한국어 데이터셋에 맞게 학습시 킨 모델 중 하나로,
네이버 뉴스 댓글 데이터셋으로 학습시켰기 때문에 신조어와 오탈자 등, 인터넷 언 어에 강하다는 특징이 있습니다.
자세한 정보는 공식 깃헙에서 확인하세요.
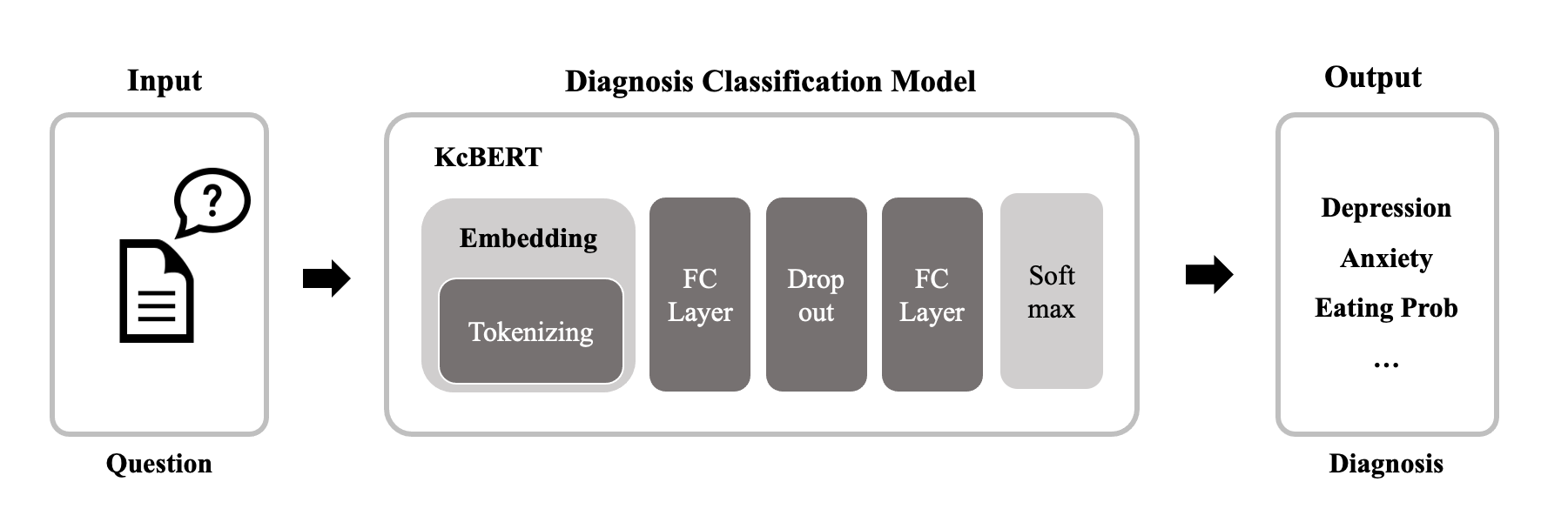
모델의 구조는 다음과 같습니다. 먼저, 입력값은 question으로 정신질환을 예측할 데이터입니다.
본 튜토리얼에서는 이 값으로 앞에서 라벨링한 데이터의 symptom 컬럼을 사용하겠습니다.
이후 입력값은 KcbertTokenizer를 통해 임베딩됩니다. 결과 벡터값은 KcBERT 모델의 레이어를 거쳐, 입력으로 받은 데이터가 어떤 정신질환에 가까운지 예측합니다.
지금부터는 이를 코드로 구현해보겠습니다.
먼저, 필요한 패키지를 임포트 합니다.
from pprint import pprintfrom pathlib import Pathimport random# torch:import torchfrom torch.utils.data import Dataset, DataLoader, TensorDataset, random_splitfrom torch.optim.lr_scheduler import ExponentialLRfrom torch import nnimport torch.nn.functional as Ffrom pytorch_lightning import LightningDataModule, LightningModule, Trainer, seed_everythingfrom pytorch_lightning.callbacks import ModelCheckpointimport pytorch_lightning as pl# transformers:from transformers import BertTokenizer, AdamW, BertModel# sklearn:from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scorefrom pytorch_lightning.loggers import TensorBoardLoggerfrom sklearn.metrics import classification_report
또, 필요한 인자를 사전에 설정해줍니다.
args = {'random_seed': 2021, # Random Seed'pretrained_model': "beomi/kcbert-base", # Transformers PLM name'pretrained_tokenizer': "beomi/kcbert-base", # Transformers Tokenizer Name'cache_dir': './models/cache','log_dir': './models/checkpoints','log_name': 'kcbert-base','version': 1,'data_path': 'data/kin_data.csv','batch_size': 16, # Train/Eval Batch Size. Overrides `auto_batch_size`'lr': 5e-5, # Starting Learning Rate, BERT paper setting [5e-5, 3e-5, 2e-5]'epochs': 5, # Max Epochs, BERT paper setting [3,4,5]'max_length': 200, # Max Length input size'report_cycle': 30, # Report (Train Metrics) Cycle'cpu_workers': os.cpu_count(), # Multi cpu workers'test_mode': False, # Test Mode enables `fast_dev_run`'optimizer': 'AdamW', # AdamW vs AdamP'lr_scheduler': 'exp', # ExponentialLR vs CosineAnnealingWarmRestarts'fp16': False, # Enable train on FP16'hidden_size': 768, # BERT-base: 768, BERT-large: 1024, BERT paper setting'hidden_dropout_prob': 0.1 # BERT paper setting}
pretrained_model과 pretrained_tokenizer에는 kcbert의 경로를 설정해줍니다.
cache_dir, log_dir, log_name, version은 체크포인트 및 캐시파일을 저장할 경로에 대한 값입니다.
data_path에는 훈련에 사용할 데이터셋의 경로를 넣어줍니다.
batch_size, learning rate, epochs 등 하이퍼 파라미터를 적절하게 설정해줍니다.
모델은 Pytorch Lightning을 이용할 것입니다. 모델 클래스에 LightningModule을 상속받습니다.
init() 함수에서는 학습에 필요한 요소 및 기능들을 정의해줍니다.
label_cols에는 라벨 컬럼의 이름을, num_labels는 클래스의 개수인 3을 설정해주고,
tokenzier는 사전학습된 KcbertTokenizer를, bert_model에는 사전학습된 Kcbert 모델을 정의해줍니다.
fc1, dropout, fc2는 파인튜닝을 위한 추가 레이어입니다.
class Model(LightningModule):def __init__(self, **kwargs):super().__init__()self.save_hyperparameters()# config:self.batch_size = self.hparams.batch_size# meta data:self.epochs_index = 0self.label_cols = 'label'self.num_labels = 3# modules:self.tokenizer = BertTokenizer.from_pretrained(self.hparams.pretrained_tokenizer,cache_dir=self.hparams.cache_dir)self.bert_model = BertModel.from_pretrained(self.hparams.pretrained_model,cache_dir=self.hparams.cache_dir)# Layers for fine-tuning:self.fc1 = nn.Linear(self.hparams.hidden_size, int(self.hparams.hidden_size/2))self.dropout = nn.Dropout(self.hparams.hidden_dropout_prob)self.fc2 = nn.Linear(int(self.hparams.hidden_size/2), self.num_labels)
forward 함수에서는 입력 데이터를 받아 순전파를 진행한 후, output을 반환합니다. output은 각 클래스에 대한 소프트맥스 값입니다.
def forward(self, data, **kwargs):# model return: (last_hidden_state, pooler_output, hidden_states, attentions)outputs_data = self.bert_model(input_ids=data, **kwargs)output = outputs_data[1] # [CLS] tokenspooled_output = self.dropout(self.fc1(output))logits = F.softmax(self.fc2(pooled_output), dim=1)return logits
옵티마이저와 스케쥴러를 정의합니다. 옵티마이저는 AdamW를 사용합니다.
def configure_optimizers(self):optimizer = AdamW(self.parameters(), lr=self.hparams.lr)scheduler = ExponentialLR(optimizer, gamma=0.5)return {'optimizer': optimizer,'scheduler': scheduler,}
데이터를 불러오고, 토크나이징 한 후, Pytorch에서 제공하는 TensorDataset 형태로 변환합니다.
이때, 저희는 입력값으로 'symptom' 컬럼을 사용할 것이므로, col_name에 'symptom'을 넣어줍니다.
TensorDataset으로부터 데이터는 <symptom, label>형태로 저장됩니다.
마지막으로 random_split함수를 통해 데이터를 8:2 비율로 train/valid셋으로 나눕니다.
def preprocess_dataframe(self):# Data load:col_name = 'symptom'df = pd.read_csv(self.hparams.data_path)df[col_name] = df[col_name].map(lambda x: self.tokenizer.encode(str(x),pad_to_max_length = True,max_length=self.hparams.max_length,truncation=True,))pprint(f"data Size: {len(df)}")# PyTorch Dataset:dataset = TensorDataset(torch.tensor(df[col_name].to_list(), dtype=torch.long),torch.tensor(df[self.label_cols].to_list(), dtype=torch.long),)# Split train/valid:lengths = [int(len(df)*0.8), int(len(df))-int(len(df)*0.8)]print("length : ", lengths)self.train_data, self.valid_data = random_split(dataset, lengths)
dataloader() 함수에서는 각 데이터를 dataloader에 전달함으로써, 학습 시 모델에 데이터를 배치 단위로 입력할 수 있도록 합니다.
def train_dataloader(self):return DataLoader(self.train_data,batch_size=self.batch_size,shuffle=True,num_workers=self.hparams.cpu_workers,)def val_dataloader(self):return DataLoader(self.valid_data,batch_size=self.batch_size,shuffle=False,num_workers=self.hparams.cpu_workers,)
아래 두 함수는 모델에 배치 사이즈 만큼의 입력을 넣어주고, Output을 받아, 이를 바탕으로 loss를 계산합니다.
다만, training_step()은 학습 단계에서, validation_step()은 학습이 끝난 후, 검증 단계에서 실행됩니다.
def training_step(self, batch, batch_idx):token, labels = batchlogits = self(token)loss = Noney_temp = torch.zeros(logits.size())for i in range(logits.size(0)):y_temp[i][labels[i]] = 1# nn.KLDivLoss:criterion = torch.nn.KLDivLoss(reduction='batchmean')loss = criterion(logits.log(), F.softmax(y_temp, dim=1).to('cuda'))return {'loss': loss}def validation_step(self, batch, batch_idx):token, labels = batchlogits = self(token)loss = Noney_temp = torch.zeros(logits.size())for i in range(logits.size(0)):y_temp[i][labels[i]] = 1# nn.KLDivLoss:criterion = torch.nn.KLDivLoss(reduction='batchmean')loss = criterion(logits.log(), F.softmax(y_temp, dim=1).to('cuda'))preds = logits.argmax(dim=-1)y_true = list(labels.cpu().numpy())y_pred = list(preds.cpu().numpy())return {'loss': loss,'y_true': y_true,'y_pred': y_pred,}
validation_epoch_end() 함수는 이름과 같이, validation이 1epoch 끝났을 때 수행됩니다.
이 함수에서는 validation 데이터셋에 대해 모델이 출력한 손실과 예측값을 바탕으로, 평균 손실과 정확도, 정확도 등의 점수를 계산하고 출력합니다.
def validation_epoch_end(self, outputs):# Loss:loss = torch.tensor(0, dtype=torch.float)for i in outputs:loss += i['loss'].cpu().detach()_loss = loss / len(outputs)loss = float(_loss)# Predicton:y_true = []y_pred = []for i in outputs:y_true += i['y_true']y_pred += i['y_pred']y_temp_pred = []for true, pred in zip(y_true,y_pred):if true == pred:y_temp_pred.append(true)else:y_temp_pred.append(pred)y_pred = np.asanyarray(y_temp_pred)y_true = np.asanyarray(y_true)self.epochs_index += 1 # epoch_end# Acc, Precision, Recall, F1metrics=[metric(y_true=y_true, y_pred=y_pred, average = 'macro')for metric in(precision_score, recall_score, f1_score)]metrics.append(accuracy_score(y_true=y_true, y_pred=y_pred))print(classification_report(y_true, y_pred, target_names=["우울장애", "불안장애", "섭식장애"]))tensorboard_logs = {'val_loss': loss,'val_acc': metrics[3],'val_precision': metrics[0],'val_recall': metrics[1],'val_f1': metrics[2],}pprint(tensorboard_logs)return {'loss': _loss, 'log': tensorboard_logs}
다음은 main() 함수입니다.
모델 객체를 정의한 후, 모델의 학습 경과를 기록할 TensorBoadLogger와 ModelCheckpoint를 정의합니다.
또, 학습과정을 컨트롤 할 Trainer객체를 선언합니다.
이후, trainer.fit(model) 코드가 실행되면, 학습 및 검증과정이 순차적으로 실행됩니다.
if __name__ == '__main__':print("Using PyTorch Ver", torch.__version__)print("Fix Seed:", args['random_seed'])seed_everything(args['random_seed'])model = Model(**args)model.preprocess_dataframe()logger = TensorBoardLogger(save_dir=args['log_dir'],version=args['version'],name=args['log_name'])checkpoint_callback = ModelCheckpoint(monitor="val_loss",dirpath="./models/checkpoints/",filename=args['log_name']+"_multi-{epoch:02d}-{val_loss:.2f}",save_top_k=1,mode="min",)print(":: Start Training ::")trainer = Trainer(callbacks=[checkpoint_callback],# callbacks=False,logger = logger,max_epochs=args['epochs'],fast_dev_run=args['test_mode'],num_sanity_val_steps=None if args['test_mode'] else 0,deterministic=True,# For GPU Setupgpus=[0] if torch.cuda.is_available() else None,precision=16 if args['fp16'] else 32)trainer.fit(model)
다음은 증상 추출 알고리즘입니다.
목표는 데이터 내에서 앞서 예측된 정신질환의 진단기준이 되는 증상을 추출하는 것입니다.
이 부분은 크게 (1) 정신질환 별 증상 사전 제작 (2) 증상 추출 알고리즘 제작으로 나눌 수 있습니다.
알고리즘은 구축된 증상 사전을 바탕으로, 데이터 내에서 진단 기준에 해당되는 정보가 포함되어 있는지 확인합니다.
먼저 증상 사전 제작 과정을 그림으로 확인해보겠습니다.
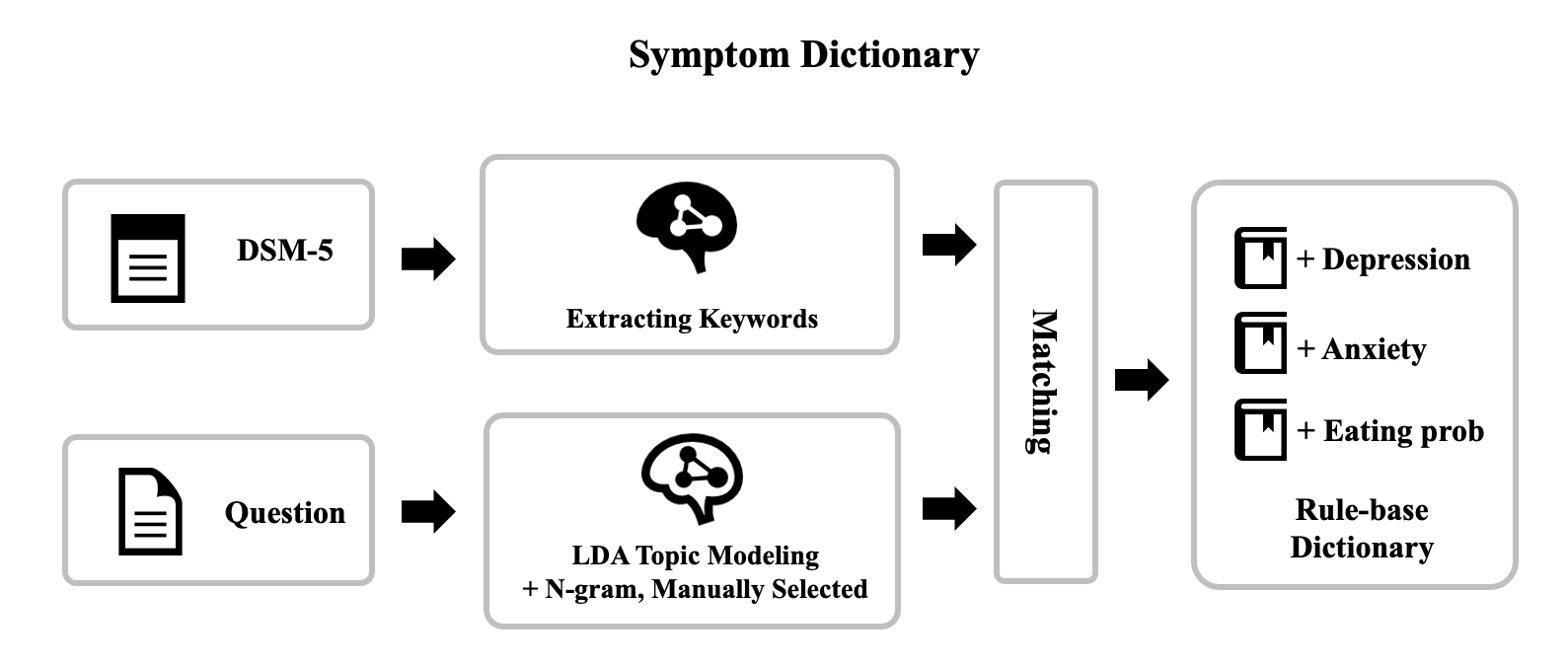
진단 기준으로는 DSM-5(Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition)가 사용되었습니다.
이 진단 기준을 바탕으로, 적절한 키워드를 추출해냅니다.
다음으로는, 라벨링한 데이터의 'symptom' 컬럼을 이용하여 데이터로부터 키워드를 추출합니다.
이때는 LDA, n-gram이 사용되었으며, 마지막으로는 직접 데이터를 확인하면서 부족한 데이터를 수동으로 추가합니다.
이후 DSM-5의 키워드와 데이터로부터 추출한 키워들을 의미에 맞게 매칭시키면, 증상 사전이 완성됩니다.
아래는 위와 같은 과정으로 구성한 우울증 증상 사전입니다.
criteria는 DSM-5로부터 추출한 진단 기준 키워드를 나타내며, keyword 컬럼은 LDA를 통해 추출한 키워드,
n-grams은 ngram을 사용하여 추출한 키워드를, Manual은 수동으로 추가한 키워드를 나타냅니다.
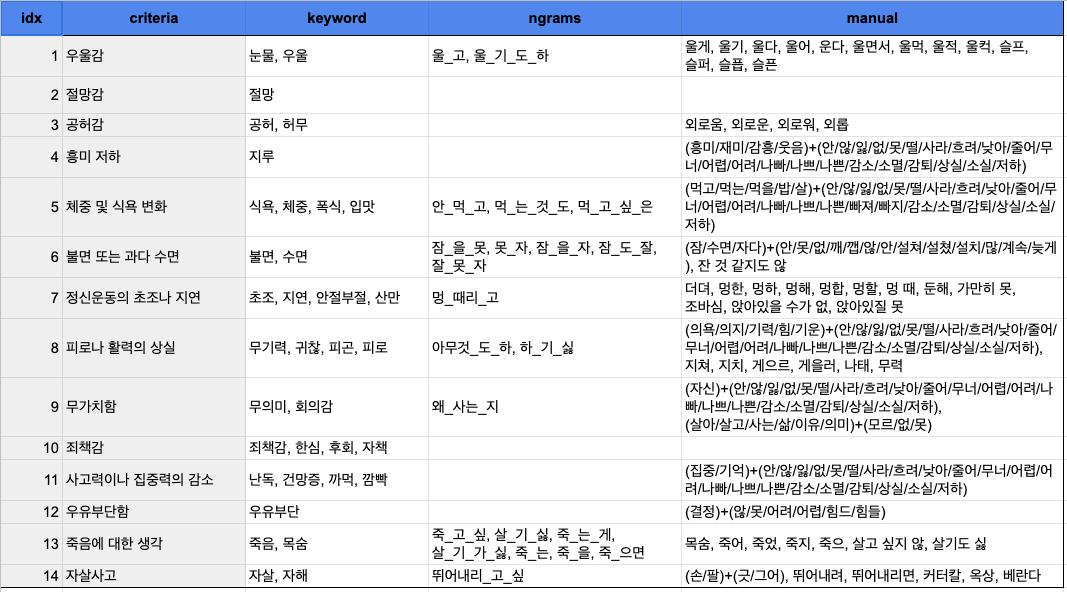
이 튜토리얼에서는 우울장애 데이터를 바탕으로, LDA와 n-gram을 통해 데이터로부터 키워드를 추출하는 과정을 보여드리겠습니다.
먼저, 필요한 패키지를 임포트 해줍니다.
from konlpy.tag import Mecabfrom tqdm.notebook import tqdmimport itertoolsfrom gensim.models.ldamodel import LdaModelfrom gensim.models.callbacks import CoherenceMetricimport gensimfrom gensim import corpora, modelsfrom gensim.models import CoherenceModelfrom nltk.util import ngramsimport kss
다음으로, 기존 데이터에서 우울장애만 분리하여 depression에 저장합니다.
depression = data[data['disorder']=="우울장애"]['symptom']pd.DataFrame(data=depression)
다음으로, 토크나이징에 필요한 함수를 정의합니다.
토크나이징은 오픈 소스 형태소 분석 엔진인 MeCab을 이용합니다.
tokenize 함수에서는 데이터를 한 row씩 처리하며, get_nouns에서는 입력으로 들어온 문장을 토크나이징해 반환합니다.
특히, nouns에서는 토크나이징된 각 토큰의 길이가 2이상이면서, 품사 중 명사, 동사, 형용사, 어근에 해당되는 것만 포함하도록 설정해두었습니다.
def get_nouns(tokenizer, sentence):tagged = tokenizer.pos(sentence)nouns = [s for s, t in tagged if t in ['SL', 'NNG', 'NNP', 'VV', 'VA', 'XR'] and len(s) > 1]print("[tokenized] : ", nouns)return nounsdef tokenize(sentences):tokenizer = Mecab()processed_data = []for sent in tqdm(sentences):print("---"*20)print("[original] : ", sent)processed_data.append(get_nouns(tokenizer, sent))return processed_data
정의한 함수를 이용해 토크나이징을 수행합니다.
depression_tokenized = tokenize(depression)
다음으로는 LDA 토픽 모델링에 사용될 함수입니다.
이에 사용된 코드의 원출처는 다음과 같습니다.
LDA는 gensim.models.wrappers.LdaMallet를 사용합니다. 먼저, 해당 모듈을 다운받겠습니다.
mallet.cs.umass.edu/dist/mallet-2.0.8.zip
위의 링크를 주소창에 입력하여, 모듈을 다운받아 프로젝트를 수행하는 폴더에 압축을 풀어주세요.
이제 함수의 각 기능을 간략하게 설명드리겠습니다.
dictionary 함수는 토크나이징한 데이터를 입력으로 받아서, 이 데이터들을 바탕으로 사전을 만듭니다. corpus에는 (token_id, token_count)가 튜플형태로 저장됩니다.
def dictionary(data_word):# make a dictionaryprint("Make a dictionary...")id2word=corpora.Dictionary(data_word)id2word.filter_extremes(no_below = 20) #20회 이하로 등장한 단어는 삭제texts = data_wordcorpus=[id2word.doc2bow(text) for text in texts]return id2word, texts, corpus
compute_coherence_values 함수는 토픽 내 일관성 지수를 계산합니다.
지정한 토픽 개수의 시작과 끝에 따라 토픽 모델이 만들어지고, 일관성 지수가 계산되어 저장됩니다.
def compute_coherence_values(dictionary, corpus, texts, start, limit, step):print("Compute coherence values...")mallet_path = 'mallet-2.0.8/bin/mallet'coherence_values = []model_list = []print("[start] : ", start)print("[limit] : ", limit)print("[step] : ", step)for num_topics in range(start, limit, step):print(num_topics, "in progress")model = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=num_topics, id2word=dictionary)model_list.append(model)coherencemodel = CoherenceModel(model=model, texts=data_word, dictionary=dictionary, coherence='c_v')coherence_values.append(coherencemodel.get_coherence())return model_list, coherence_values
LDA 함수는 토픽 모델링 모듈을 정의하고, 일관성 지수를 계산한 모델을 반환받아, 가장 일관성 지수가 높은 객체와 결과값을 반환합니다.
모듈을 선언할 때 주는 인자로 중, num_topics는 각 토픽에 포함될 키워드의 개수를 의미합니다.
def LDA(data_word, Data_list, start, limit, step):id2word, texts, corpus = dictionary(data_word)# create lda instanceprint("Create LDA instance...")mallet_path = 'mallet-2.0.8/bin/mallet'ldamallet = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=20, id2word=id2word)# calculating coherence to find optimal k (the number of topics)coherence_model_ldamallet = CoherenceModel(model=ldamallet, texts=texts, dictionary=id2word, coherence='c_v')coherence_ldamallet = coherence_model_ldamallet.get_coherence()# Can take a long time to run.model_list, coherence_values = compute_coherence_values(dictionary=id2word, corpus=corpus, texts=texts, start=start, limit=limit, step=step)x = range(start, limit, step)topic_num = 0count = 0max_coherence = 0for m, cv in zip(x, coherence_values):print("Num Topics =", m, " has Coherence Value of", cv)coherence = cvif coherence >= max_coherence:max_coherence = coherencetopic_num = mmodel_list_num = countcount = count+1# Select the model and print the topicsoptimal_model = model_list[model_list_num]model_topics = optimal_model.show_topics(formatted=False, num_words=30)return optimal_model, model_topics
입력할 데이터는 두 가지 입니다.
data_word에는 앞서 토크나이징한 데이터를 입력해주며, Data_list에는 토크나이징 하지 않은 데이터를 입력해줍니다.
start, limit, step에는 각각 토픽의 개수의 시작과 끝, 그리고 증분을 설정해줍니다.
- data_word = depression_tokenized #tokenized data
- Data_list = depression #untokenized data
- start=3; limit=5; step=1; #the number of topics
- ##------check------##
- print(Data_list[0])
- print("\n", np.array(data_word[0]))
LDA 코드를 실행합니다.
- model, topics = LDA(data_word, Data_list, start, limit, step)
topics를 출력하여 결과를 확인할 수 있습니다.
- topics
이제는 n-gram을 바탕으로 키워드를 추출해봅시다.
n_gram은 nltk.util 에서 제공하는 ngrams 함수로 쉽게 추출할 수 있습니다.
먼저 토크나이징을 해줄 건데, 아까와 달리 모든 형태의 토큰을 포함한 형태로 토크나이징 해줍니다. get_nouns() 함수만 좀 조정해주면 됩니다.
def get_nouns(tokenizer, sentence):tagged = tokenizer.pos(sentence)nouns = [s for s, t in tagged]# nouns = [s for s, t in tagged if t in ['SL', 'NNG', 'NNP', 'VV', 'VA', 'XR'] and len(s) > 1]print("[tokenized] : ", nouns)return nouns
다음으로, ngrams함수를 이용하여 series데이터가 입력으로 들어왔을 때, 각 row별로 ngram을 추출해 저장하도록 해줍니다.
아래는 이를 수행하는 make_ngram함수입니다.
두 번째 파라미터 ngram으로 단위를 정할 수 있습니다. 1이면 uni-gram, 2이면 bi-gram, 3이면 tri-gram이 추출됩니다.
def make_ngram(series, ngram):res = []for i in tqdm(range(len(series))):res.append(["_".join(w) for w in ngrams(series[i], ngram)])return res
토크나이징을 수행합니다.
depression_t2 = tokenize(depression)
바이그램을 만듭니다.
depression_bigram = make_ngram(depression_t2, 2)depression_bigram[7]
트라이그램을 만듭니다.
depression_trigram = make_ngram(depression_t2, 3)depression_trigram[7]
만들어진 토큰들을 빈도 순으로 정렬하여 어떤 키워드가 제일 많이 등장하는지 확인해보겠습니다.
ngram_frequency()함수는 itertools를 이용해 각 row로 나뉘어져 있는 ngrams들을 통합한 후에, value_counts로 빈도를 출력합니다.
5번 이상 등장하지 않은 ngram은 제외하고, csv파일로 저장합니다.
def ngram_frequency(ngram, filename):data = list(itertools.chain(*ngram))cnt = pd.Series(data).value_counts()cnt = cnt[cnt >= 5]cnt.to_csv("data/depression_"+filename+".csv")return cnt
cnt_trigram = ngram_frequency(depression_trigram, "trigram")cnt_bigram = ngram_frequency(depression_bigram, "bigram")
또, LDA와 ngram으로 추출불가한 키워드들은 수동으로 추가해줍니다.
증상 사전의 예시를 보면, ''(흥미/재미/감흥/웃음)+(안/않/잃/없/못/떨/사라/흐려/낮아/줄어/무너/어렵/어려/나빠/나쁘/나쁜/감소/소멸/감퇴/상실/소실/저하)''와 같이, (target)+(matched) 형태로 구성된 요소들이 있는데, 이는 (target)단어가 등장하면서 뒤에 (matched)단어가 등장한 것을 찾는다는 룰입니다.
(흥미/재미/...)와 같이 그 자체의 키워드만으로는 증상 기준에 포함되기 어렵고,
뒤에 부정을 의미하는 단어가 동반되어야 비로소 진단 기준에 해당된다고 볼 수 있는 단어들을 처리하기 위해 이와 같은 룰이 사용되었습니다.
그럼, 완성된 증상 사전을 바탕으로 증상 추출 알고리즘을 구축해보겠습니다.
미리 저장해둔 증상 사전을 아래 링크에서 다운받으실 수 있습니다.
Download Dictionary (Depression)
저장한 증상 사전을 불러옵니다.
dic = pd.read_excel('data/depression_symptom_list.xlsx')dic
이렇게 구성된 증상 사전은 각 row내 포함된 요소들이 리스트 형태로 저장될 수 있도록 전처리를 해두겠습니다.
def dic_preprocess(dic):word_list = ['keyword', 'ngrams', 'manual']for word in word_list:for i in range(len(dic)):target = dic[word][i]try:if target[-1] == ",":target = target[:-1]if "," in target:temp = target.split(", ")else:temp = [target]dic[word][i] = tempexcept:passreturn dic
keys = dic_preprocess(dic)keys
각 행에 포함된 세 가지 키워드들이 리스트 형태로 저장된 모습을 볼 수 있습니다.
다음은 토크나이징된 데이터에 대해 간단한 전처리를 해두겠습니다.
기존의 토크나이징된 데이터는 이중 리스트로 구성이 되어 있었는데, 이를 1차원 리스트로 변경해주는 작업입니다.
def merge_elements(series):# merge each sentence's elementsres = []for i in range(len(series)):merged = " ".join(series[i])res.append(merged)print("length of data : ", len(res))return res
depression_t = merge_elements(depression_t2)
다음은 증상 추출 알고리즘입니다. 알고리즘은 총 세 가지 함수로 구성되어 있습니다.
check_matched_word 함수는 앞에서 언급했던 (target)+(matched) 형태의 룰을 처리하는 함수입니다.
target 단어가 등장한 문장에서 뒤에 matched 단어가 등장하는지 확인합니다. 맞다면 True를, 아니라면 False를 반환합니다.
def check_matched_word(sentence, target, match, criteria):print("\n*check whether two types of words are matched..", "\n[target]", target, "⇢", criteria)for sent in kss.split_sentences(sentence):for word in target:if word in sent:print("[matched sentence]", sent)for m in match:fw = sent.find(word)fn = sent.find(m, fw)if m in sent and fw < fn and (fn-fw) < 8:print("True!")return Trueprint("False!\n")return False
dep_keyword_extractor() : 우울장애 데이터와 증상 사전의 키워드를 매칭하는 함수입니다.
기본적으로는 증상 사전의 키워드가 입력 데이터 내에 포함되어있는지 확인하다가, '(' 형태를 만나면, 위의 check_matched_word를 실행합니다.
반환값은 키워드로부터 매칭된 진단 기준(criteria)입니다.
def dep_keyword_extractor(sentence, key_list, key_type):res = []keywords = key_list[key_type]for i in range(len(keywords)):if str(keywords[i]) != 'nan':for word in keywords[i]:# key_type: ngramsif key_type == "ngrams":ngram = word.replace("_", " ")if ngram in sentence:print("\n>> matched!", ngram, "⇢", key_list['criteria'][i])res.append(key_list['criteria'][i])# key_type: keyword, manualelse:# (target)+(match) typeif word[0] == '(':st_target = 1ed_target = word.find(')')st_match = word.find('(', ed_target)+1ed_match = word.find(')', st_match)target = word[st_target:ed_target].split('/')match = word[st_match:ed_match].split('/')if any(w in sentence for w in target):if check_matched_word(sentence, target, match, key_list['criteria'][i]):print("\n>> matched!", word, "⇢", key_list['criteria'][i])res.append(key_list['criteria'][i])# normal typeif word in sentence:print("\n>> matched!", word, "⇢", key_list['criteria'][i])res.append(key_list['criteria'][i])return res
symptom_extractor 함수는 필요한 데이터들을 입력받아 for문을 통해 각 데이터로부터 증상을 추출하는 함수입니다.
하나의 데이터에 대해 각 세가지 타입의 키워드들을 바탕으로 dep_keyword_extractor()가 실행되며, 모든 결과를 모아 중복을 제거한 뒤, 최종적으로 추출된 증상을 반환합니다.
def symptom_extractor(symptom, symptom_tokenized, key_list, disorder):symptom_result = []# type of disorderif disorder == "depression":function = dep_keyword_extractorelif disorder == "eating disorder":function = die_keyword_extractorelif disorder == "anxiety":function = anx_keyword_extractorelse:print("Error! Please enter one of the following disorders: 'depression', 'eating disorder', 'anxiety'.")# symptommptom extractionfor i in tqdm(range(len(symptom))):temp = []print("\n", "------"*5, i, "------"*5)print("\n[Target Sentence]\n\n", "t >> ", symptom[i])print("\n####### keyword #########")temp.append(function(symptom[i], key_list, key_type="keyword"))print("\n####### ngrams #########")temp.append(function(symptom_tokenized[i], key_list, key_type="ngrams"))print("\n####### manual #########")temp.append(function(symptom[i], key_list, key_type="manual"))temp = list(itertools.chain(*temp))temp = list(set(temp))symptom_result.append(temp)print("\n[Result] : ", temp)return symptom_result
입력으로는 그냥 데이터, 토크나이징된 데이터, 증상 사전, 그리고 기준이 되는 정신질환을 입력합니다.
- symptom = symptom_extractor(depression, depression_t, keys, "depression")
지금까지 정신 건강 데이터를 이용하여, 두 가지 NLP기반의 응용 모델을 구축해보았습니다.
튜토리얼이 도움이 되었길 바랍니다.
감사합니다.
[참고문헌]
1. Tadesse, M. M., Lin, H., Xu, B., &Yang, L. (2019). Detection of depression-related posts in reddit social media forum. IEEE Access, 7, 44883-44893.
2. 최진화, 이구상, 유혜림, 서지혜, 김은지, 전홍진. (2021). 유족과의 면담을 통한 자살 자 심리부검과 경찰 수사기록 조사를 통한 자살자 심리부검 결과 비교. Journal of Korean Neuropsychiatric Association, 60(1), 61-69.

