

- 제 1조 . 본 사용 허가 협약에 동의하여 서명한 협약서를 한국전자통신연구원(이하 제공자)에 제출한 사람만이 본 데이터셋을 본 협약의 내용에 따라 보유하고 사용할 자격을 갖는다.
- 제 2조 . 본 데이터셋은 제공자의 서면 승인 없이 제3자에게 제공, 양도, 사용 허가할 수 없다.
- 제 3조 . 본 데이터셋은 연구용도로만 사용이 가능하며, 상업용으로 사용은 불허한다.
- 제 4조 . 본 데이터셋이 협약자로 인해 유출되어 문제가 발생하였을 경우 본 협약자는 민, 형사상의 모든 법정 책임을 부담한다.
한국어 음성 감정 데이터셋 (KESDy18)
- 등록자 노경주
- 등록일 (수정일 ) 2020-07-22 05:40 (2025-06-16 15:20)
- 조회수 13392
- 다운로드 수
- 추가업로드 불가
-
 휴먼이해
휴먼이해

좋아요
협약서
필요
(제출전)
Description
데이터 셋 소개
한국어 기반 음성감정 데이터셋(Korean Emotional Speech Dataset: KESDy18)은 음성기반 감정 인식(Speech Emotion Recognition: SER) 기술 연구를 위해 헤드셋 마이크(Shure S35) 장치를 통해 수집한 음성데이터에 대한 데이터셋이다(2018.04~2018.09).
데이터셋 이관 안내
**본 KESDy18 데이터셋은 2025.06.02 이후 다운로드 서비스가 중단되었습니다.
데이터 수집 절차
- 총 30명의 한국인 성우(남/여 각 15명)를 대상으로 제자리 서기(정적)/제자리 걷기(동적)의 신체상태에서 특정 문장을 발화하는 과정에서의 성우의 음성데이터를 수집하였다. 성우는 정적/동적 상태에서 4가지 카테고리 감정(중립, 행복, 슬픔, 분노)을 표현하며 각 감정 카테고리당 20문장의 한국어 문장을 발화하였다.
- 한국어를 모국어로 사용하는 성인 6명의 감정 레이블 평가자가 성우가 발화한 각 문장을 청취 한 후, 각 문장에 대한 자신이 느끼는 7개의 카테고리 감정 레이블 (기쁨, 놀람, 분노, 중립, 혐오, 공포, 슬픔) 중 1개를 선택하고, 5단계(1~5)의 각성도(arousal)와 긍/부정도(valence)를 평가하였다.
데이터 셋에 포함되는 감정 레이블 평가 파일(SER-DB-ETRIv18_emotion_label_annotation.xlsx)은 각 발화 음성(세그먼트)에 대한 평가 통계 정보를 포함한다. 각 발화 세그먼트 별 최종 카테고리 감정레이블에 대한 평가는 평가자의 다수 선택을 받은 카테고리 감정 레이블로 결정(동일 평가 수를 갖는 경우에는 중복 레이블로 설정)되고, 각성도와 긍/부정도는 각 평가자의 평균값으로 계산되었다.
- Arousal : (이완) 1-2-3-4-5 (각성)
- Valence : (부정) 1-2-3-4-5 (긍정)
데이터 셋 구성
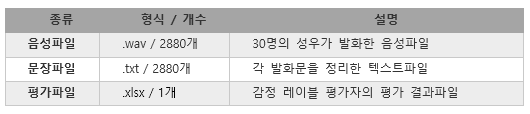
출판
한국어 기반 음성감정 데이터셋의 수집은 한국전자통신연구원 연구운영비지원사업의 일환으로 수행되었다[18ZS1100, 자율성장형 AI 핵심원천기술 연구].
본 데이터셋을 사용한 논문, 연구결과 발표자료에는 아래의 본 데이터과 관련한 연구논문에 대한 사사문구를 포함하여야 한다.
Noh, K.J.; Jeong, C.Y.; Lim, J.; Chung, S.; Kim, G.; Lim, J.M.; Jeong, H. Multi-Path and Group-Loss-Based Network for Speech Emotion Recognition in Multi-Domain Datasets. Sensors 2021, 21, 1579. https://doi.org/10.3390/s21051579
디렉토리 구성

데이터
파일
(총
1 개)

KESDy18
요약 KESDy18

- 등록자 노경주
- 파일명 KESDy18.zip
- 크기 207.7MB
- 다운로드 수
KESDy18

