- Korean Emotion Multimodal Database
in 2020 (KEMDy20)
KEMDy20
is a multimodal emotion data set that collects speech data, text data
transcribed from the speech, and bio-data such as electrodermal activity (EDA),
Inter-Beat-Interval (IBI), and wrist skin temperature during the free-talking
process between two speakers.
The
collecting procedure of KEMDy20 is approved by the institutional review board
of the Korea national institute for bioethics policy (P01-202009-12-001).
·
KESDy18 : Korean Emotional Speech Dataset in
2018
https://nanum.etri.re.kr/share/kjnoh2/KESDy18?lang=En_us
·
KEMDy19 : Korean Emotion Multimodal Database in 2019
https://nanum.etri.re.kr/share/kjnoh2/KEMDy19?lang=En_us
A
total of 80 adults between the ages of 19 and 39 who are proficient in Korean
speech were grouped with two participants, and each group participated in one
session (a total of 40 sessions) to collect data. In each session, two
participants wear Empatica E4 devices on their wrists, watch a 5-minute video
on the subject, and then have a free-talking with the other participant for 5
minutes or so. Each group repeats the process of viewing and speaking freely on
the 6 theme videos. Speech data, transcription text of the speech data, and
speaker bio-signal data of two participants were collected during the
conversation on six topics of the subjects. The subject's free-talking was
video-recorded.
The
10 external taggers evaluated the speech segments while listening to the
recorded utterances. The annotators tagged one of seven categorical emotion
labels (“angry”, “sad”, “happy”, “disgust”, “fear”, “surprise”, “neutral”).
And, they tagged labels of arousal (low-high: 1-5) and valence-level
(negative-positive: 1-5) on a 5-point scale for each segment.
The
final categorical emotion label was determined by a majority vote. The label of
arousal and the valence-level were determined from the average value of the
levels tagged by the evaluators.
|
Directory
|
File
extension
|
Explanation
|
|
./annotation
|
.csv
|
Emotion label file tagged by
the external annotators by session/participant/utterance data
|
|
./wav
|
.wav /
.txt
|
Wav file of speech data in
session/free-talking/(.wav)
Transcription text file of
speech data in session/free-talking /(.txt)
|
|
./EDA
|
.csv
|
EDA data collected through E4
device by session/free-talking/participant
|
|
./IBI
|
.csv
|
IBI data collected through E4
device by session/free-talking/participant
|
|
./TEMP
|
.csv
|
Wrist temperature data
through E4 device by session/free-talking/participant
|
· ./wav/~/.txt : usage of special characters
|
Special
character
|
Usage
|
|
c/
|
Continuous vocalization
without a speechless period(less than 0.3 seconds)
|
|
n/
|
Episodic noises Included in
speech data
|
|
N/
|
Speech data contains more
than 50% noise
|
|
u/
|
Speech data that cannot be
understood verbally
|
|
l/ (small 'L')
|
Speech data includes
‘Um/Uh/mm’ sound
|
|
b/
|
Speech data includes breath
or cough sounds
|
|
*
|
Recognizing only some of the
words in speech data
|
|
+
|
Repetitive stuttering during vocalization
|
|
/
|
Interjection included in
speech data
|
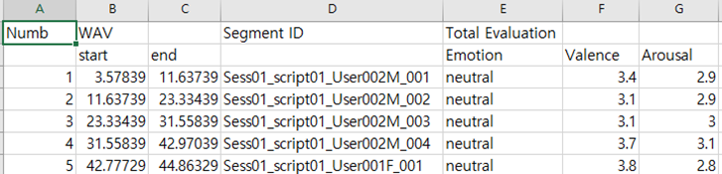
· ./annotation/.csv
· ./EDA/session1~40/.csv
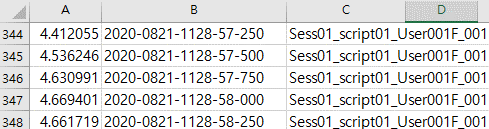
- col. A :
E4 EDA change value of consecutive samples
- col. B : Time
order of the data measurement
- col. C :
Segment ID to which the corresponding EDA value belongs
· ./IBI/session1~40/.csv

- col. A : E4 sampling period sequence
- col. B : E4 IBI value
- col. C : Time order of the data
measurement
- col. D : Segment ID to which the
corresponding ECG value belongs
· ./TEMP/session1~40/.csv

- col. A :
Wrist temperature of E4
- col. B : Time
order of the data measurement
- col.
C : Segment ID to which the corresponding EDA value belongs
Publication
[1] K. J. Noh and H. Jeong, “KEMDy20,” https://nanum.etri.re.kr/share/kjnoh2/KEMDy20/update?lang=En_us
[2] NOH, Kyoungju; JEONG, Hyuntae. Emotion-Aware Speaker Identification with Transfer Learning. IEEE Access, 2023.






